Introduction
The AWS Certified Data Engineer – Associate is a professional credential that sits at the intersection of software engineering and data science. It is designed to certify that a professional can handle the entire lifecycle of data on the AWS platform. This includes everything from the initial ingestion of streaming data to the complex transformation logic required for high-end analytics. It is a technical certification that demands a deep understanding of how various AWS services can be stitched together to create a seamless, automated data ecosystem.
Why it matters in today’s software, cloud, and automation ecosystem
We are living in an “AI-First” world, but AI is only as good as the data it is fed. In today’s ecosystem, the role of the data engineer is considered the most critical link in the chain. Without a robust data pipeline, automation fails, and business intelligence becomes inaccurate. This certification is important because it shifts the focus from “Infrastructure-as-Code” to “Data-as-a-Product.” It ensures that the systems being built are not just functional but are also scalable, resilient, and capable of handling the massive data volumes seen in modern enterprises.
Why certifications are important for engineers and managers
For the individual engineer, a certification is a tool for self-actualization. It forces a departure from “tribal knowledge” and pushes the learner toward globally recognized best practices. It provides a structured learning path that prevents the gaps in knowledge often found in self-taught professionals. For engineering managers, these certifications are essential for building a high-trust culture. When a team is certified, a baseline of technical competence is established. This reduces the time spent on basic technical reviews and allows the leadership to focus on high-level strategic goals and innovation.
Certification Overview Table
| Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
| Data Engineering | Associate | SREs, DevOps, Data Engineers | Foundational AWS knowledge | Data Pipelines, ETL, Governance, Security | Post-Solutions Architect Associate |
Provider: DevOpsSchool
Why Choose DevOpsSchool?
DevOpsSchool is consistently chosen by industry veterans because it transcends the traditional “certification dump” model. The focus is placed heavily on the “Why” behind the technology, not just the “How.”
- Mentorship-Driven: Learning is facilitated by mentors who have spent decades in production environments, offering insights that are not found in official documentation.
- Lab-Centric Curriculum: The training is built around intensive, hands-on labs that simulate real-world outages and data corruption scenarios.
- Evolving Content: As AWS releases new features for services like Glue or Redshift, the curriculum is updated in real-time, ensuring the learner is always at the cutting edge.
- Career Support: Beyond the exam, a strong emphasis is placed on resume building and technical interview preparation for senior roles.
Certification Deep-Dive
What is this certification?
This certification is a specialized technical credential. It focuses on the architectural and operational tasks required to manage data at scale. It is the bridge between traditional backend engineering and modern data science operations.
Who should take this certification?
This path is ideal for professionals who find themselves responsible for the “plumbing” of the cloud. If you are a Software Engineer tired of writing boilerplate CRUD operations, or a DevOps Engineer looking to specialize in the high-growth data sector, this is the intended path for you.
Skills you will gain
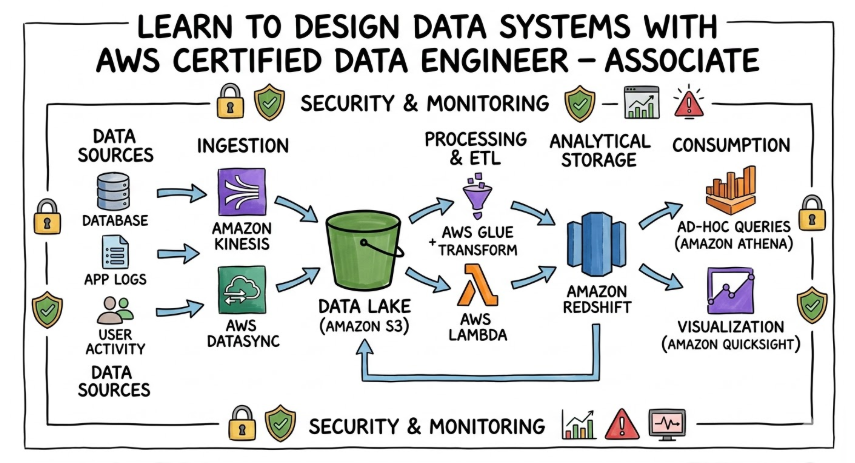
- Advanced Data Ingestion: Mastery over tools like AWS Kinesis and MSK is achieved, allowing for the handling of millions of events per second in real-time.
- Serverless ETL Orchestration: Deep knowledge of AWS Glue is developed, including the ability to write custom Spark scripts and manage the Glue Data Catalog for enterprise-wide discovery.
- Data Lake Architecture: The skill to design “Lakehouse” architectures on S3 is gained, ensuring that data is stored in the most efficient formats like Parquet or Avro.
- Security & Compliance Mastery: A thorough understanding of fine-grained access control is acquired, ensuring that sensitive data is masked and encrypted according to global standards like GDPR or HIPAA.
- Performance Tuning: The ability to optimize complex SQL queries in Redshift and manage compute scaling in EMR is mastered, ensuring high-speed analytics for the business.
Real-world projects you should be able to do
- End-to-End Real-Time Pipeline: A system is built where website clickstream data is captured by Kinesis, processed by Lambda, and stored in Redshift for immediate dashboarding.
- Automated Data Quality Framework: A pipeline is created that automatically detects “dirty” data, moves it to a quarantine S3 bucket, and alerts the engineering team via SNS.
- Enterprise Data Governance Portal: Using AWS Lake Formation and Glue, a central portal is designed where different departments can share data securely without duplicating storage.
- Cost-Optimized Archival System: An automated lifecycle policy is engineered to move petabytes of data from S3 Standard to Glacier Deep Archive based on access patterns, saving thousands of dollars monthly.
Preparation Plan
- 7–14 Days Plan: This is a “Sprint” approach. The focus is placed on reviewing the “AWS Exam Readiness” digital training. Every evening is spent taking timed mock exams. The last three days are dedicated purely to reading the “FAQs” of Glue, S3, Redshift, and Athena.
- 30 Days Plan: This is the “Professional” approach. The first two weeks are spent on “Deep Service Study,” where one major service is mastered every two days. The third week is dedicated to “Lab Work,” where at least five complex data pipelines are built from scratch. The final week is used for “Gap Analysis” based on practice test results.
- 60 Days Plan: This is the “Mastery” approach. The first month is dedicated to “Broad Context,” learning how data engineering integrates with DevOps and Security. The second month is “Drill-Down,” where edge cases, CLI commands, and complex IAM scenarios are memorized and practiced.
Common mistakes to avoid
- Underestimating the Theory: Many engineers fail because they know the “buttons” to click but do not understand the underlying concepts of data partitioning or sharding.
- Ignoring IAM: A significant portion of the exam is about “Who can see the data.” Failing to master IAM policies and Lake Formation permissions is a common pitfall.
- Focusing Only on One Tool: AWS often tests your ability to choose the best tool. Knowing when to use Athena versus Redshift is critical for success.
Best next certification after this
- Same track: AWS Certified Data Analytics – Specialty (for deeper visualization and reporting).
- Cross-track: AWS Certified Solutions Architect – Professional (for broad enterprise mastery).
- Leadership / management: AWS Certified Cloud Practitioner or an MBA in Technology Management.
Choose Your Learning Path
- DevOps: This path focuses on Data-as-Code. You learn to deploy data pipelines using Terraform or CloudFormation. This is best for those who want to automate the delivery of data.
- DevSecOps: This path emphasizes the Secure Pipeline. You learn to integrate automated vulnerability scanning and data encryption into the ETL flow. This is best for engineers in highly regulated industries.
- Site Reliability Engineering (SRE): This path is about Data Reliability. You focus on error budgets for data jobs and setting up “Self-Healing” pipelines. This is best for those who manage the uptime of big data clusters.
- AIOps / MLOps: This path is the Fuel for AI. You learn how to prepare feature stores and clean data specifically for SageMaker. This is best for engineers working on the cutting edge of machine learning.
- DataOps: This is the Pure Lifecycle path. You master everything from the moment a bit is created until it is deleted or archived. This is best for dedicated Data Engineers.
- FinOps: This is the Economic Path. You focus on “Cost per Query” and ensuring that the data platform is profitable for the business. This is best for lead engineers and architects.
Role → Recommended Certifications Mapping
- DevOps Engineer: Combine AWS SysOps with Data Engineer Associate to bridge the gap between infra and data.
- Site Reliability Engineer (SRE): Combine CKA (Kubernetes) with Data Engineer Associate to manage data on containers.
- Platform Engineer: Combine AWS Solutions Architect Pro with Data Engineer Associate to build the foundation for the whole company.
- Cloud Engineer: Combine AWS Developer Associate with Data Engineer Associate to build data-driven applications.
- Security Engineer: Combine AWS Security Specialty with Data Engineer Associate to become a data privacy expert.
- Data Engineer: The core is Data Engineer Associate followed immediately by Data Analytics Specialty.
- FinOps Practitioner: Combine Cloud Practitioner with Data Engineer Associate to understand the cost of every byte.
- Engineering Manager: Combine PMP with Data Engineer Associate to lead technical teams with authority.
Next Certifications to Take
To maintain a competitive edge, the following certifications are recommended:
- One same-track certification: Google Professional Data Engineer is recommended to gain a multi-cloud perspective and understand BigQuery versus Redshift.
- One cross-track certification: HashiCorp Certified: Terraform Associate is recommended because modern data pipelines must be deployed via code, not manual clicks.
- One leadership-focused certification: Certified Kubernetes Administrator (CKA) is recommended because more data processing is moving toward containerized environments like EKS.
Training & Certification Support Institutions
DevOpsSchool
This institution is recognized for its “Industry-First” approach. The training is not just about passing an exam; it is about surviving your first day as a Senior Data Engineer. Extensive post-training support is provided to ensure students can apply their knowledge in production environments.
Cotocus
Cotocus specializes in high-impact corporate transitions. They are the preferred partner for large firms looking to upskill their entire backend team into modern data engineering. Their curriculum is highly structured and focuses on organizational efficiency.
ScmGalaxy
A powerhouse of documentation and community knowledge. For the self-motivated engineer, this platform offers thousands of technical articles and guides that dive into the smallest details of AWS data services.
BestDevOps
This platform is tailored for the “Modern Engineer.” It focuses on the intersection of cloud and code, providing streamlined modules that are easy to digest but technically deep.
devsecopsschool.com
The ultimate destination for “Security-First” engineering. They teach how to build data systems that are “unhackable” by design, focusing on encryption, masking, and auditing.
sreschool.com
Focused on the “Art of Reliability.” Here, engineers learn how to build systems that don’t wake them up at 3 AM. The focus is on observability, monitoring, and fault tolerance.
aiopsschool.com
This institution bridges the gap between traditional operations and artificial intelligence. They teach how to manage the massive datasets required for modern AI modeling.
dataopsschool.com
A dedicated home for the DataOps movement. They focus on the agility of data—how to move fast without breaking the data quality.
finopsschool.com
This school teaches the “Business of Cloud.” It is essential for anyone who needs to prove the ROI (Return on Investment) of their technical decisions to the CFO.
FAQs Section
Core Industry Questions
- Is this cert harder than the Solutions Architect Associate?
Yes, it is generally considered more difficult because it requires a deeper dive into specific tools like Spark, SQL, and data modeling. - How much time should I set aside daily?
For a working professional, 90 minutes of focused study per day is recommended to clear the exam in 6 weeks. - What is the “Associate” level?
It means you are expected to know how to do the work, not just design it. It is a technical, hands-on level. - Do I need a degree in Data Science?
No. This is an engineering certification. If you can write code and understand logic, you can succeed. - Is the market for Data Engineers saturated?
Quite the opposite. There is a massive shortage of engineers who actually understand how to build reliable pipelines. - Can I transition from DevOps to Data Engineering?
Yes, this certification is the perfect “bridge” for that transition. - Is Python or Scala better for the exam?
Python is more widely used in the exam questions and in the industry for AWS Glue. - How often does AWS update the exam?
AWS updates its exams every 2-3 years, but services are added to the exam as they become “General Availability.” - What if I fail the exam?
You can retake it after 14 days, but you must pay the full fee again. - Is there a lab in the actual exam?
Most current versions are multiple-choice, but they are “mini-scenarios” that test if you have actually used the console. - Will this certification help with “Remote Work”?
Yes, cloud data engineering is one of the most remote-friendly roles in tech. - Is SQL still relevant?
Absolutely. SQL is the “Universal Language” of data and is heavily tested.
AWS Data Engineer – Associate Specifics
- How deep is the “Glue” coverage?
Very deep. You must understand Crawlers, Classifiers, Blueprints, and the difference between Spark and Python shells. - What is tested regarding Redshift?
You must know about Distribution Keys, Sort Keys, and the “Redshift Spectrum” feature for querying S3. - How much “Athena” is on the exam?
A significant amount. You must know how to optimize queries and how Athena integrates with the Glue Data Catalog. - Is “Migration” a big topic?
Yes. Knowing how to use AWS DMS (Database Migration Service) and Snowball for large-scale moves is essential. - What about “EMR”?
You need to know when to choose EMR over Glue and how to manage “Spot Instances” for cost savings. - Is “Governance” just about permissions?
No. It’s also about data lineage, auditing via CloudTrail, and data cataloging. - What is the “Lakehouse” concept?
It is the combination of a Data Lake (S3) and a Data Warehouse (Redshift). You must know how they work together. - Is “Step Functions” important?
Yes, it is the primary way to orchestrate complex, multi-service data workflows on AWS.
Testimonials
Deepak (Senior DevOps)
The perspective on data as “Live Infrastructure” was a game-changer. After completing this certification, the ability to automate the entire data lifecycle using Terraform was gained. It has made me indispensable to my current team.
Saritha (SRE)
The “Reliability” of our pipelines was always a headache. This course provided the technical depth needed to implement automated retries and dead-letter queues. The confidence growth has been measurable.
Jason (Cloud Engineer)
Transitioning from a generalist to a specialist was the goal. The AWS Data Engineer path provided the roadmap. The focus on real-world projects meant that the skills were applied on day one.
Maria (Security Lead)
Data privacy is the biggest risk for our company. Understanding Lake Formation and KMS through this certification allowed for a complete overhaul of our data security. It was a career-defining move.
Rahul (Engineering Manager)
Building a data-driven culture starts with a certified team. I took the exam to lead by example. The strategic clarity gained has allowed for more efficient project timelines and better hiring practices.
Conclusion
The AWS Certified Data Engineer – Associate is more than just a certificate on a wall. It is a fundamental shift in how one approaches technology. In an industry where “Data is the New Oil,” the engineers who can refine that oil are the ones who will lead the next generation of companies. By investing in this path through proven institutions like DevOpsSchool, you are not just learning a tool; you are future-proofing your career. Start with a plan, stay consistent, and become the engineer that every modern company is searching for.